|
||||
Издатель: Algorithm Online При поддержке ORACLE в России Техническая поддержка официальный дистрибутор ORACLE |
Определенные пользователем события в Oracle Enterprise Manager1 июля 2000 г. User-Defined Events in OEM, by Albert Balbekov Альберт Бальбеков
Oracle Publish Online, February, 2000 Добавление в Oracle Enterprise Manager версии 2.0.4 пользовательских скриптов для проверки событий может еще более усилить его и без того мощные возможности мониторинга и позволит не терять адресованных вам уведомлений в тех случаях, когда отказывают некоторые части системы. Автоматические возможности мониторинга Oracle Enterprise Manager (OEM) очень легко могут испортить вас [в смысле, приучить к хорошей жизни, прим. переводчика]. Все, что от вас требуется – это создать набор стандартных событий, а OEM с помощью специальных программ – Intelligence Agent – станет отслеживать проблемы с дисковым пространством, производительностью и отказами компонент (выходом из строя узлов, баз данных и программ прослушивания сети). Но что делать в том случае, если вам необходимо обнаруживать ситуации, которые не входят в перечень стандартных событий OEM, например, отказ какого-либо сервера приложений или даже самого сервера управления Oracle (Oracle Management Server – OMS)? Я несколько месяцев успешно использовал для мониторинга за узлами и базами данных OEM версии 2.0.4, как вдруг обнаружилось, что на протяжении двух дней я не получаю почту от OEM. Когда я проверил OMS, который несет ответственность за посылку почты внутри OEM, выяснилось, что он был закрыт после того, как было потеряно его соединение с репозиторием OEM. В OEM версии 2.0.4 можно сконфигурировать несколько экземпляров OMS, но все они должны иметь одну и ту же базу данных репозитория и, следовательно, все они в случае недоступности базы данных репозитория будут закрыты без уведомления администратора. Таким образом, мне необходима система для автоматического мониторинга OMS и уведомления об его отказах. Поскольку OEM версии 2.0.4 не предоставляет вам способа реализации определенных пользователем событий в рамках системы событий, вы можете писать на языке Tcl (tool command language – язык команд инструментального средства) собственные скрипты, которые осуществляют проверку событий и выполняются с использованием системы заданий OEM. В том случае, если вы хотите использовать для уведомления OMS, ваши скрипты могут даже взаимодействовать с системой событий OEM как дополнительные события, используя для этого добавленную в версию Tcl для Oracle команду orareportevent. Однако, поскольку в описываемом мною случае событием, которое необходимо обнаружить, является отказ самого OMS, необходимо, чтобы оповещение осуществлялось независимо от OEM с использованием обработки сообщений по протоколу SMTP. В этой статье описывается примененный мною для создания системы мониторинга OMS подход, использующий два скрипта Tcl, тексты которых прилагаются. Эти скрипты работают совместно, чтобы в случае отключения или недоступности OMS можно было гарантировать администратору получение уведомления по протоколу SMTP. Кроме того, в статье приводятся рекомендации по модификации этих скриптов и созданию ваших собственных систем отслеживания событий для использования в среде OEM. Пользовательские системы отслеживания событий: как они работают Когда вы составляете пользовательский скрипт для проверки событий, который будет выполняться в среде OEM, вы хотите, чтобы он действовал аналогично собственным проверкам событий OEM. Как и в случае проверки событий OEM, вы определяете условие, которое должно проверяться программным обеспечением Oracle Intelligent Agent (оно приходит вместе с дистрибутивом Oracle) и о выполнении которого вы хотите получить сообщение. Однако, вместо того, чтобы выбирать стандартные события системы управления событиями (Events Management System) OEM, вы определяете их (точнее, условия при которых эти события происходят) в скрипте Tcl, который выполняется как задание в системе планирования заданий (Job Scheduling System) OEM. (Для знакомства с тем, как пишутся скрипты Tcl, сходите на страницу Getting Started with Tcl (http://dev.scriptics.com/scripting) на Web-сайте Tcl Developer Xchange). В вашем скрипте вы можете использовать любой из двух методов уведомления о событии:
Поскольку нам требуется уведомить администратора именно в случае выхода из строя OMS, для предлагаемых в этой статье скриптов используется метод уведомления по SMTP. Однако их можно модифицировать и использовать в них метод незапрашиваемых событий, если он кажется вам более предпочтительным (см. раздел “За и против метода незапрашиваемых событий”). Хотя первое, что приходит в голову, это запускать написанный вами скрипт как периодически выполняемое задание, – то есть, использовать для определения частоты повторения задания систему заданий OEM – я настоятельно рекомендую вам использовать для этой цели бесконечный цикл с заложенным внутрь скрипта интервалом ожидания. Конечно, при использовании этого подхода требуется дополнительное программирование, но я предпочитаю его подходу планируемых заданий по следующим причинам: Если вы не желаете запускать одно и то же предупреждение несколько раз, вам необходимо для каждого прогона задания знать результаты его предыдущего выполнения. Планируемые задания выполняются соответствующими программами (Intelligence Agents) как отдельные процессы ОС, которые заканчиваются вместе с закончившимся заданием. Поэтому не существует другого способа выяснить статус предыдущих прогонов задания, как хранить их (статусы) в базе данных или в файле, что существенно усложняет как процесс написания скрипта, так и процесс его выполнения. При использовании же бесконечного цикла процесс никогда не заканчивается и, следовательно, может содержать всю свою историю. Кроме того, часто выполняемые задания могут создавать нежелательную нагрузку на уровне ОС, поскольку процесс разветвляется при каждом выполнении. При использовании же подхода с бесконечным циклом, мы, естественно, имеем всего один прогон задания, и разветвляется только один процесс. Поэтому, хотя возможность планирования заданий OEM и кажется удобнее, я предпочитаю вставлять в мой скрипт бесконечный цикл. Подход с бесконечным циклом не является совершенным. В нем на каждую проверку создается свой процесс, что я считаю излишней тратой системных ресурсов (в мою систему входят четыре задания по мониторингу, из которых здесь обсуждаются только два). Кроме того, в то время как стандартные задания Oracle Events и планируемые задания не требуют перерегистрации в случае отказов или рестартов Intelligence Agent, задания с бесконечным циклом должны быть повторно запущены вручную. А это означает, что если вы не хотите, чтобы рестарты стали проблемой, вы можете иметь для каждой программы-агента всего лишь несколько заданий с бесконечным циклом. Тем не менее, поскольку при применении подхода с бесконечным циклом становится возможным создавать определенные пользователем события полностью в среде системы событий, мне кажется, что этот подход представляет наиболее удобный и эффективный способ выполнения проверки событий пользователем. Пример мониторинга OMS Целью моей системы мониторинга является уведомление администратора в случае выхода из строя OMS, поскольку отказ OMS приводит к тому, что исходящая почта из OEM остается не отправленной. Для достижения этой цели мне пришлось написать два задания на Tcl: одно для выполнения с помощью Intelligence Agent на сервере управления (Management Server), а другое – на управляемом узле (Managed Node). Прежде чем мы углубимся в детали этих заданий, давайте бросим взгляд на общую архитектуру системы, изображенной на Рис. 1.
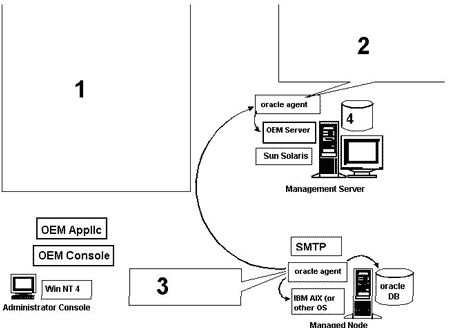
Рис. 1. Oracle Enterprise Manager в действии На рис.1. цифрами обозначены следующие тексты и надписи 1. Основным при создании пользовательской системы текущего контроля за событиями в Oracle Enterprise Manager (OEM) 2.0.4 является написание пользовательских скриптов на языке Tcl для выполнения задач мониторинга с последующей передачей их на выполнение программному обеспечению Intelligence Agent на соответствующих узлах (средствами системы заданий OEM). Стрелки на приведенной “архитектурной” диаграмме указывают на объекты, за которыми ведут мониторинг соответствующие агенты описываемой в этой статье системы проверки событий, разработанной для гарантированного оповещения администратора в случае отказа OMS. Система текущего контроля обрабатывает сбои следующим образом:
2. Сначала выполняется скрипт CheckOMS.tcl, который проверяет, работает ли OMS:
Во-вторых, выполняется скрипт CheckOMSAgent.tcl, проверяющий, работает ли агент на управляемом узле:
3. Проверка заранее определенных событий, относящихся к узлу или базе (базам) данных. (Не требуется пользовательских скриптов на Tcl), как задано в системе событий OEM. 4. Репозиторий OEM Некоторые моменты этой архитектуры требуют отдельных объяснений. Во-первых, OMS находится на том же узле, что и репозиторий OEM, потому что, по моему опыту, в том случае, если разместить их на разных узлах, это может привести к проблемам с производительностью. Во-вторых, Intelligence Agent, проверяющий, работает ли OMS, расположен на том же узле, что и сервер управления. Я разместил его именно там, потому что агент должен иметь возможность запустить утилиту oemctrl (исполнимый модуль, поставляемый в составе OEM), а эта утилита отсутствует для платформы AIX (на которой работает управляемый узел). Стоит также отметить, что, хотя для работы консоли администратора в моей системе используется Windows NT, для этой консоли можно использовать Windows 95 или 98, Sun Solaris или один из поддерживаемых OEM браузеров Web с возможностью работы с Java (если были установлены Web-сайты OMS). Аналогично, сервер управления может вместо Sun Solaris использовать Windows NT, а управляемый узел использовать для баз данных любую поддерживаемую Oracle платформу. Стрелки на Рис. 1 показывают область ответственности обеих программ Intelligence Agent. Программа-агент на сервере управления выполняет скрипт CheckOMS.tcl (обсуждается в следующем разделе, текст приведен в листинге 1), который проверяет, работает ли OMS, и в случае выхода его из строя через SMTP уведомляет об этом администратора. Программа-агент на управляемом узле выполняет скрипт CheckOMSAgent.tcl (описывается в следующем разделе, текст приводится в листинге 2), который проверяет, работает ли агент на сервере управления, и в противном случае с помощью SMTP оповещает администратора. Кроме того, агент на управляемом узле осуществляет проверку множества стандартных событий, имеющих отношение к самому управляемому узлу и к его базам данных (включение/выключение хост-машины и базы данных, зондирование (probe), файл предупреждений, дисковое пространство и т.п.). Конечно, для проверки этих стандартных событий программе-агенту не требуется написанный пользователем скрипт, так как проверка этих событий создается в рамках системы событий OEM. Изображенная на Рис. 1 система мониторинга обрабатывает сбои входящих в нее компонент, а именно:
Чтобы понять, как обрабатываются первые два типа отказов, нам необходимо поближе познакомиться с выполняемыми агентами скриптами. Знакомство со скриптами Оба скрипта на языке Tcl, выполняющие в моей системе заказанный пользователем мониторинг событий, весьма похожи по своим методам. Скрипт CheckOMS.tcl (листинг 1), выполняемый агентом на сервере управления, проверяет, работает ли OMS? У скрипта имеется три параметра. Первый – OMS_connect_string – обеспечивает строку, необходимую для подключения агента к OMS. В моем случае в эту строку не нужно включать спецификацию пункта назначения, так как и агент, и OMS выполняются на одном и том же узле. Прежде, чем выполнять скрипт, я создал в среде OEM пользователя Administrator, имя и пароль которого используются в скрипте. Второй параметр – sleeptime – определяет интервал времени в секундах, которое проходит между двумя последовательными проверками (время ожидания). Третий параметр – smtp_addr – определяет почтовый адрес, по которому в случае сбоя должно быть послано уведомление. Так как после выхода из строя OMS нет ничего взамен системы коммуникаций OEM, я использовал утилиту Unix mailx, для которой требуется работающая система SMTP. Если вы модифицируете этот скрипт для выполнения в среде Windows NT, вам придется взамен mailx использовать почтовую утилиту SMTP для Windows, которая называется blat. Blat – это общедоступное программное обеспечение для Windows 95 или Windows NT, которое можно найти на сайте его разработчика (http://gepasi.dbs.aber.ac.uk/softw/blat.html) и которое посылает содержимое файла как сообщение электронной почты, используя для этого протокол SMTP. При выполнении скрипта циклически повторяются следующие шаги: определенное время он (скрипт) находится в состоянии ожидания, затем “просыпается”, чтобы проверить, работает ли OMS (используя для этого поставляемый в составе OEM исполняемый модуль oemctrl), и снова переходит в состояние ожидания. Если проверка установила, что OMS не работает, скрипт посылает уведомление, используя для этого утилиту mailx. Если при следующей проверке OMS снова не будет работать, повторное уведомление не посылается. Проверки будут продолжаться до тех пор, пока работоспособность OMS не будет восстановлена. В этом случае посылается сообщение “OMS is up”. Скрипт CheckOMSAgent.tcl (листинг 2), который выполняется агентом управляемого узла, проверяет, работает ли агент на сервере управления. Он использует тот же самый подход, что и CheckOMS.tcl, и имеет аналогичный набор параметров (dns_name, sleep_time и notify_smtp_address). Он так же использует для уведомления администратора обмен сообщениями по протоколу SMTP как страховку от случая, когда выходят из строя как OMS, так и агент на сервере управления (весьма вероятный сценарий в случае выхода из строя всего узла). Как и для скрипта CheckOMS.tcl, для работы в среде Windows вы можете модифицировать его, воспользовавшись для обмена сообщениями по SMTP утилитой blat. Конечно, если вы модифицируете эти скрипты для мониторинга за чем-то, отличным от OMS, и желаете использовать стандартное уведомление OEM о событии, вам не нужны утилиты типа mailx или blat и вам не требуется параметр с адресом оповещения администратора. Вы просто используете команду Tcl orareportevent, чтобы доложить о событии непосредственно в OEM. Модификация и выполнение скриптов на вашей системе Если вы хотите реализовать на вашей системе процесс мониторинга за OMS, вы должны иметь возможность выполнять приведенные в листингах 1 и 2 скрипты без существенных модификаций. Однако даже в таких случаях вам все-таки потребуется небольшая отладка, и уж тем более вы должны иметь представление о процессе отладки, если вы захотите более существенно модифицировать эти скрипты (например, контролировать другие специализированные (зависящие от приложения) события или использовать для оповещения администратора метод незапрашиваемых событий). Поэтому, прежде чем вести речь о выполнении скриптов Tcl, мы немного поговорим о том, как их отлаживать. Отладка скриптов Tcl Для разработки и отладки скриптов Tcl в среде OEM не существует никаких специальных инструментальных средств. По существу, вы можете выбрать один из двух методов: использование Oracle Agent или использование исполнимого модуля oratclsh (команда интерпретатора Tcl). Чтобы использовать для отладки скрипта Oracle Agent, вы должны выполнить следующие шаги:
Так как использование для отладки скриптов Oracle Agent может оказаться весьма медленным (в моей среде проходило около минуты, прежде чем я мог увидеть результаты выполнения), вы можете предпочесть ему использование исполнимого модуля oratclsh, инсталлированного вместе с Oracle Agent. Для того, чтобы проверить, как работает конкретная команда, прежде чем включить ее в скрипт, я использую интерпретатор командной строки Tcl. Однако имейте в виду, что команды в среде oratclsh могут не давать точно того же результата, к которому они приводят в среде Oracle Agent. К примеру, если в среде под управлением Unix вы наберете “ls”, вы получите распечатку содержимого текущей директории, потому что oratclsh, если у него нет собственной версии команды, пытается выполнить соответствующую команду ОС. Однако Oracle Agent не выполнит команду “ls” в переданном ему на выполнение скрипте, поэтому скрипт завершится аварийно. Примечание: Прежде чем использовать oratclsh на платформе Unix, вы должны установить значение переменной TCL_LIBRARY равным "$ORACLE_HOME/network/agent/tcl". Выполнение скриптов Tcl Используя систему заданий OEM, очень легко разместить скрипт Tcl для выполнения в Intelligent Agent. Для этого вы, находясь в среде консоли OEM, должны выполнить следующие шаги:
После того, как вы передали скрипт на выполнение, вы получите сообщение от системы заданий OEM, в котором сообщается, что задание стартовало (в OEM версии 2 это является услугой по умолчанию). Затем задание появляется на панели Jobs консоли OEM со статусом “running”. Во время выполнения задание может послать сообщение на консоль OEM, используя для этого команду orajobstst (в моем скрипте эта команда используется для того, чтобы отображать предупреждения на консоли OEM). Чтобы увидеть эти предупреждения, вам достаточно дважды щелкнуть мышью на имени выполняющегося задания на консоли OEM. Если в любой момент времени вам потребуется прекратить выполнение задания, для этого достаточно выполнить с консоли команду Remove Job из меню Job. Если скрипт “упал” сам, OEM посылает уведомление “Job failed” (это также является услугой по умолчанию для OEM версии 2). Агенты всегда начеку Если вы хотите расширить вашу автоматическую систему отслеживания событий за рамки стандартных событий, предлагаемых OEM, самое время подумать об использовании пользовательских скриптов на языке Tcl. Пользуясь указаниями и примерами, приведенными в этой статье, вы можете легко реализовать собственные системы текущего контроля за OMS или расширить существующие системы и создать собственные подсистемы проверки событий, происходящих в конкретном приложении (application-specific event-checking system), связанные с OEM. Ведь, в конце концов, у вас есть все эти Intelligence Agents, которые только и ждут, чтобы помочь вам. Так почему же не воспользоваться ими? Об авторе: Альберт Бальбеков (Albert Balbekov – Abalbekov@grtcotp.com) является старшим консультантом фирмы GRT Inc. в Стэмфорде, шт. Коннектикут. Последние пять лет он работает с базами данных Oracle. За и против метода незапрашиваемых событий Описываемая в этой статье система текущего контроля не использует возможности незапрашиваемых событий OEM, но в некоторых случаях вы можете использовать их для создания собственных систем текущего контроля за событиями. В основном эта возможность обеспечивает для OEM способ перехватывать уведомления о событиях, пришедшие извне системы событий OEM, для того, чтобы сообщение о таких событиях появлялись на консоли OEM. Вам по-прежнему нужно создавать собственную систему обнаружения событий, но вы можете сделать так, чтобы сообщения о них передавались непосредственно в OEM одним из следующих способов:
В любом случае вы сообщаете значения необходимых системе событий параметров (eventname, object, severity и message) в соответствии с синтаксисом, описанным в руководстве Oracle Enterprise Manager Application Developer's Guide. По сравнению с методом оповещения о событиях, использованным в описанной в статье системе текущего контроля за событиями (в котором используемый для обнаружения события скрипт Tcl посылает сообщение SMTP непосредственно администратору) метод незапрашиваемых событий имеет следующие преимущества:
Однако у метода незапрашиваемых событий имеется один существенный недостаток, обсуждавшийся ранее: для уведомления администратора он полностью полагается на OMS, и, следовательно, вы не можете использовать его, если вам требуется уведомить администратора даже в том случае, если OMS вышел из строя. Имеется и еще один недостаток, который может оказаться как важным, так и не слишком важным для вас: размер сообщения электронной почты, генерируемого незапрашиваемыми событиями, может оказаться слишком большим для многих пейджеров – момент, достойный упоминания, если вы часто получаете уведомления на свой пейджер. . |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||